Establishing SRE Culture in Optimizely DXP
Autor
Mikhail Syvachenko
Software Developer
bei SYZYGY Techsolutions
Lesedauer
8 Minuten
Publiziert
20.10.2025

Every new feature adds complexity faster than old issues can be resolved. Simply “keeping the lights on” only delays the inevitable – a major incident that disrupts both business and team. Reliability isn’t about throwing more money at support; it’s about building smart, intentional processes that prevent failures before they happen.
This article introduces key principles of Site Reliability Engineering (SRE) within the context of the Optimizely DXP PaaS ecosystem. It is intended for architects, engineers, and digital teams looking to improve platform stability, reduce operational overhead, and establish a more resilient digital foundation.
From Silent Degradation to Fast Recovery
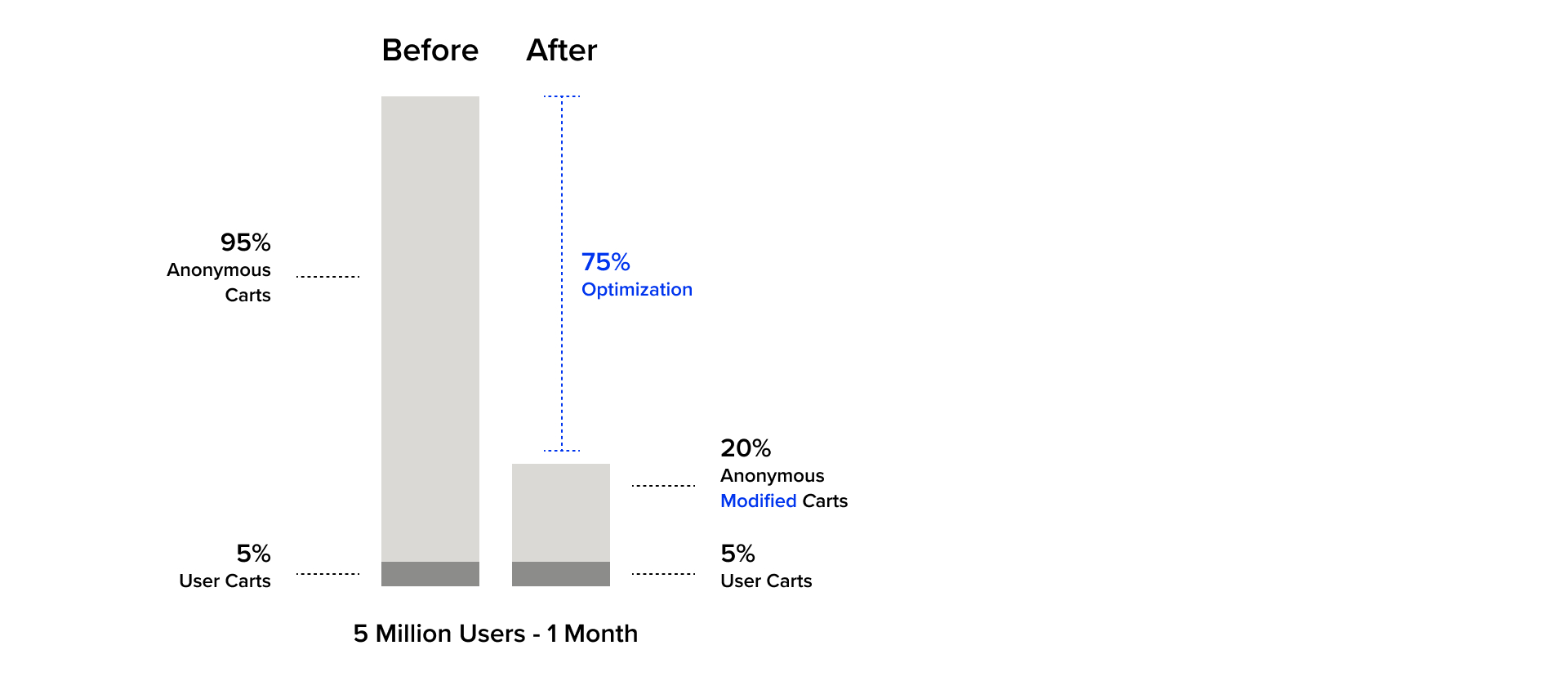
Recently, we observed an unexpected pattern on a major ecommerce platform: the system began creating millions of shopping carts – hundreds of thousands per day – without any immediate alarm. The impact was subtle but dangerous: over time, these carts bloated the database, increased system load, and gradually slowed down the platform. If left unchecked, this issue would have escalated into severe service degradation, with slower database queries and, ultimately, SQL timeout exceptions impacting user experience and revenue.
The key differentiator was the pre-established foundation of SRE practices. Proactive database monitoring and custom analysis scripts allowed us to quickly localize the root cause before the problem exploded. With this insight, we deployed a targeted fix: new visitors would receive in-memory carts instead of persistent database entries. This led to a sharp drop in system load, stabilized database health, and transformed the near-miss into an improvement.
Two Approaches to Reliability
Ensuring high reliability for digital platforms requires a systematic and balanced approach, combining both proactive and reactive actions.
- Proactive phase is a strategic preparation process. It includes design, implementing automated tests, configuring monitoring and telemetry, and identifying risk zones and potential failure points. Here, practices like Definition of Done (DoD) and Definition of Ready (DoR) play a key role in maintaining quality at every stage of the development lifecycle. Well-structured proactive work helps minimize the likelihood of outages and creates conditions for effective incident response.
- Reactive phase involves promptly detecting and resolving incidents, followed by analysis and root cause remediation. Reactive processes are critical for timely responses to unforeseen events caused by human error, vendor-side changes, infrastructure modifications, or previously undiscovered vulnerabilities. A properly designed reactive strategy ensures platform resilience in real-world production scenarios.
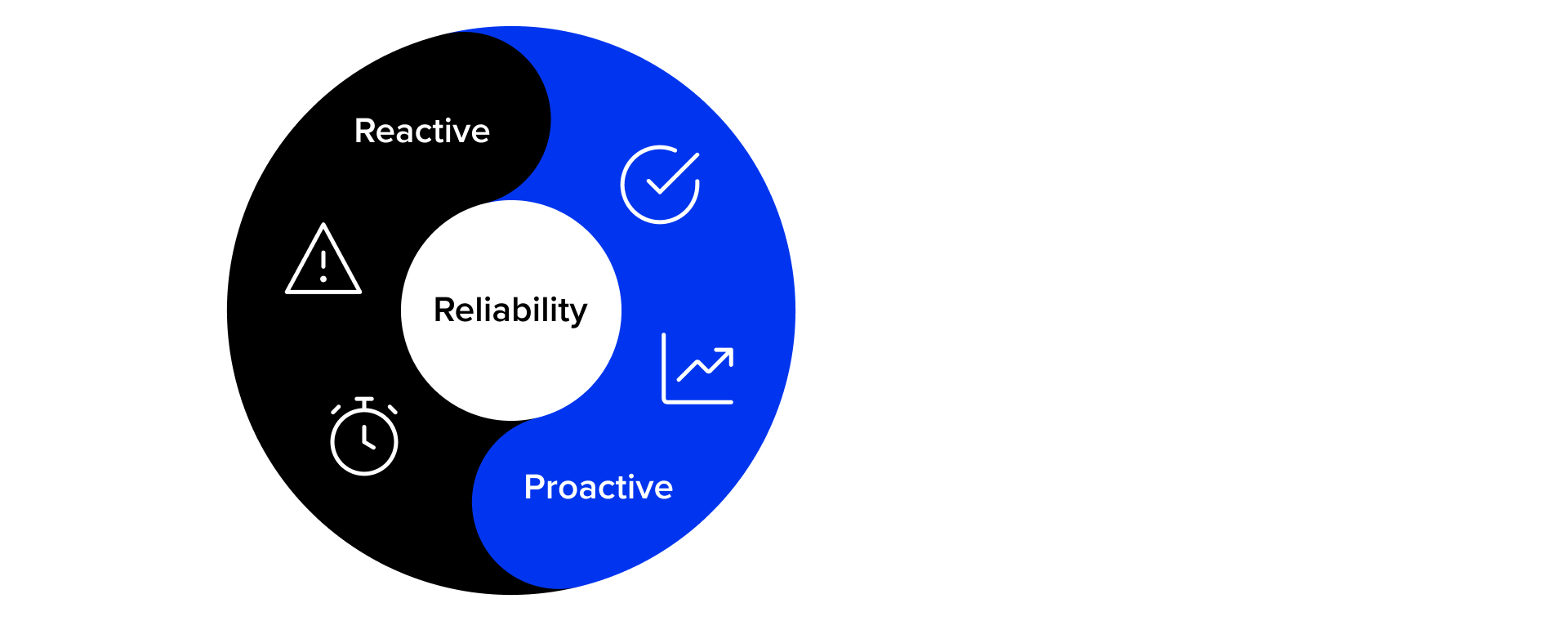
It’s important to emphasize that proactive and reactive actions are not opposites – they complement each other. Proactive preparation lays the foundation for fast and accurate responses to incidents, saving resources and reducing stress on the team. Together, these approaches provide the level of reliability required for modern DXP solutions to thrive.
How “Proactive” Empowers “Reactive”
Real platform resilience and high reliability are achieved not so much by quick reactions to incidents, but by the quality of the data and tools the team has prepared in advance. Every successful incident resolution is the result of a well-constructed system of monitoring, logging, and diagnostics.
Reliability engineering for DXP involves continuous monitoring, anomaly detection, analysis of incorrect behavior patterns, and rapid restoration of operability. Yet the effectiveness of each step depends directly on how systematically data about errors, events, and metrics is collected and made available.
Data Sources
Identifying relevant data sources for each application segment is a critical first step. In Optimizely DXP, Azure ecosystem services play a central role – Application Insights for telemetry collection, Log Analytics for log aggregation and dashboarding, as well as third-party monitoring systems such as Cloudflare (analytics and security at the CDN level), Pingdom (external synthetic monitoring) or custom health-check mechanisms, and extensible solutions like Splunk. This multi-layered approach allows failures to be detected both at the platform and at the user experience level.
However, proper setup of logging processes and data ingestion systems is not a one-off action, but a dynamic, continuously evolving process that demands regular review and deep analysis. Mistakes at this stage – such as excessive or insufficient log detail, information duplication, lack of unified formatting standards – often lead to critical data being unavailable when it’s needed most. Moreover, excessive log verbosity can overload infrastructure, increase data storage costs, and complicate subsequent analysis.
It’s equally important to consider how third-party libraries and external services influence data flow. These integrations demand extra care: validate and standardize their logs, enforce security checks, and ensure compliance with internal policies. Many libraries use custom formats or may expose sensitive data, so plan ahead to avoid leaks and simplify incident analysis.
From Profiling to Tracing
The next key stage is the selection and configuration of analysis tools. Having rich data sources means little without proper interpretation: root causes are often hidden in non-obvious correlations between metrics or error traces. This is where specialized profiling and diagnostics tools become indispensable, e.g.: PerfView for deep CPU and memory analysis, JetBrains dotTrace for identifying performance bottlenecks, and standard utilities for working with network connections (netstat, dnsutils) to analyze load and service availability at the OS level. But the list doesn’t end there: in practice, dozens of other tools and platforms are used – and each of these shines in non-standard, complex situations where problems fall outside typical patterns and require creative analytical approaches.
A team’s familiarity with tools and best practices directly impacts response speed and accuracy. During an incident, there’s no time to search for the right tool or learn its basics. Proactive exploration of platform features, reading expert blogs, and scenario-based drills are key to building maturity.
The line between proactive and reactive work is thin: every preparation step is an investment for when intervention becomes inevitable. Organized data sources, tool proficiency, and structured processes enable fast response and continuous learning – reducing failures over time.
Processes and Culture in DXP
Long-term stability and reliability of a DXP platform are only possible if all project participants – from developers and testers to managers and business stakeholders – adhere to a unified set of rules and principles, share a common vision, and possess a transparent understanding of key processes. This covers everything from designing architecture and writing code to reviewing pull requests, implementing automated tests, and formalizing quality requirements at each development stage.
A culture of reliability is established when the team goes beyond code-writing and consciously builds out incident response processes: defining clear escalation protocols, maintaining internal communication channels, promptly conducting post-mortems, and holding retrospectives. In such retrospectives, mistakes are examined not to assign blame, but to uncover root causes, distill lessons learned, and avoid future recurrences.
Customer involvement also takes on particular importance within the DXP ecosystem. Their engagement, timely feedback, and clear articulation of business expectations enable developers and managers to prioritize effectively, make rapid decisions, and respond flexibly to changing conditions. Especially in stressful, critical situations, the customer’s input often carries significant weight, sometimes determining the final course of action. It is therefore essential to foster a transparent environment rooted in mutual trust and open communication – where customers are not mere observers, but active participants supporting the team and helping achieve expected outcomes.
Breaking into SRE
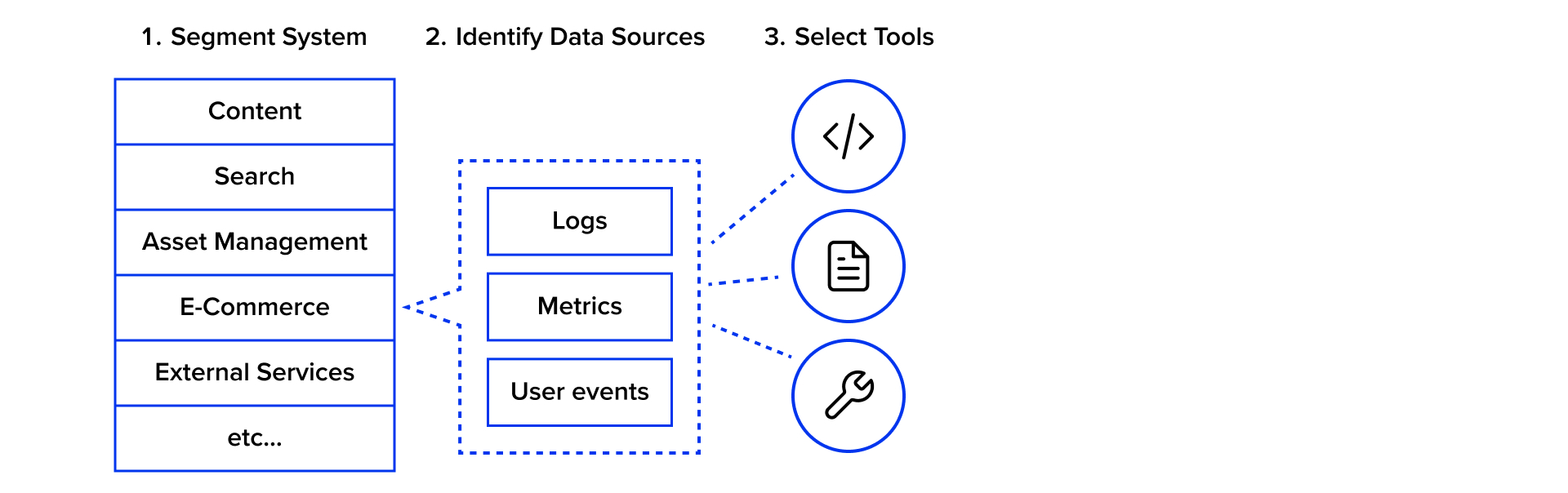
For teams starting with Site Reliability Engineering, a good first step is a structured analysis of the DXP platform areas you manage:
- Segment the system – Break it down into key areas: content, search, asset management, ecommerce, external services, etc.
- Identify data sources – Determine which logs, metrics, and user events are available for each segment.
- Select the right tools – Choose instruments that can interpret and visualize this data effectively.
This approach creates a solid foundation for improving reliability, streamlining detection and remediation, accelerating response, and building a stable, predictable platform.
Conclusion
In this publication, only the fundamental aspects of ensuring DXP platform reliability were covered, focusing on the balance between proactive and reactive approaches, the importance of processes and culture, and the practices of data collection and analysis.
However, the toolkit of modern Site Reliability Engineering teams contains a whole spectrum of additional tools and approaches worthy of special attention. Among these are automation of monitoring and response (auto-healing, self-remediation), implementation of CI/CD for resilience testing, architectural patterns such as chaos engineering, incident management practices based on SLA and SLO, integration with observability platforms, advanced alerting and escalation methods, end-to-end security processes, and many more.
Each of these topics can become an independent growth point for your team and help optimize both day-to-day operations and the response to complex, non-standard situations. It is important not to view SRE as a collection of isolated techniques, but as a sequential and integrated culture in which every action is aimed at maximizing the resilience and manageability of digital services.
By building a strong SRE culture, you lay the groundwork for scaling your business, increasing customer loyalty, and succeeding in the digital landscape.

Head of Technology