Beschleuniger, aber kein Ersatz für bewährte Praktiken
Autor
Michael Wolf
Head of Technology
bei SYZYGY Techsolutions
Lesedauer
8 Minuten
Publiziert
08.07.2025

Generative KI beschleunigt Coding, Tests und Dokumentation enorm. Gleichzeitig belegen aktuelle Feldstudien einen Anstieg technischer Schulden sowie sinkende Lieferqualität. Wie lässt sich dieses Spannungsfeld auflösen?
Schon 2023 prognostizierte Gartner, dass bis 2027 über 70 % aller Entwickler:innen KI für die Entwicklung nutzen werden. Das ist kaum verwunderlich, denn KI kann die Produktivität und Code-Qualität deutlich erhöhen.
Aktuelle Feldstudien nennen zweistellige Produktivitätssprünge – berichten aber ebenso von wachsender technischer Schuld und Durchsatzverlust auf Systemebene. Wir werfen einen Blick darauf, weshalb Laborgewinne selten direkt im Projekt ankommen und welche Governance-Hebel nachhaltigen Erfolg beim Einsatz von KI sicherstellen können.
Disclaimer zu Zahlen & Grafiken
Die gezeigten Diagramme dienen der Veranschaulichung: Alle Zahlen sind Beispielwerte, die sich an aktuellen Studien orientieren, aber keine exakten Originaldaten wiedergeben.
Produktivitätsgewinne
Die ersten Studien über mögliche Produktivitätsgewinne durch KI-Nutzung in der Softwareentwicklung entstanden Anfang 2023, z. B. The Impact of AI on Developer Productivity: Evidence from GitHub Copilot. Etwa 100 professionelle Entwickler:innen mussten einen HTTP-Server in JavaScript implementieren; eine Gruppe durfte KI nutzen, die Kontrollgruppe nicht. Mit KI waren die Teilnehmenden im Median über 50 % schneller.
Solche Ergebnisse lassen sich aufgrund des sehr kleinen Versuchsaufbaus und einer sehr individuellen Aufgabe natürlich schwer auf die tägliche Arbeit von Entwicklungsteams übertragen. Aktuelle Studien zeigen aber, dass sich Produktivitätseffekte inzwischen auch jenseits kleiner Laboraufbauten bestätigen lassen.
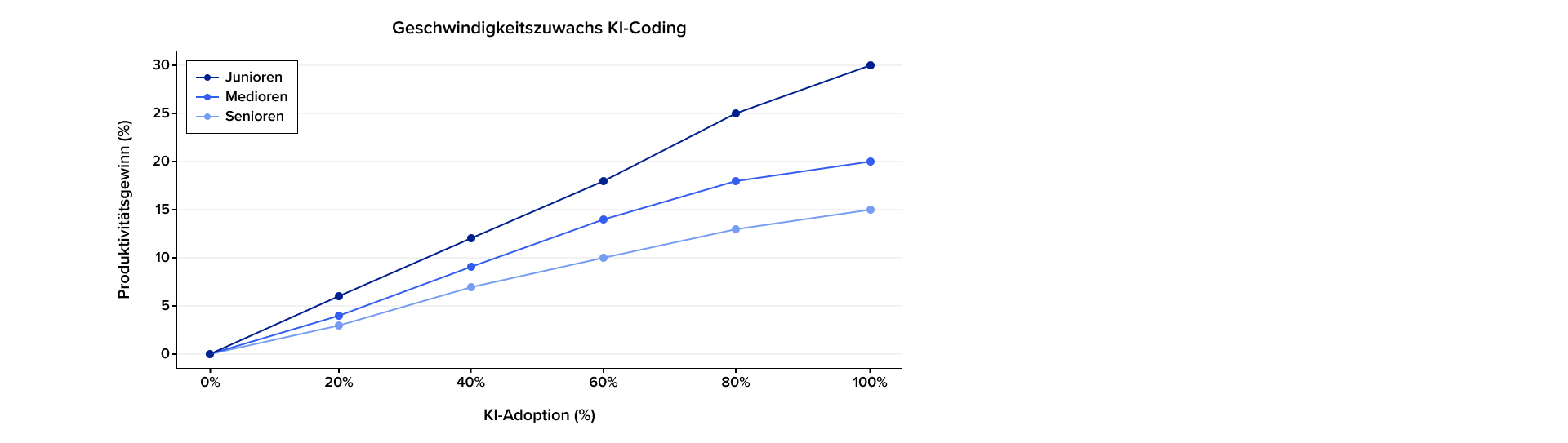
Die Studie The Effects of Generative AI on High-Skilled Work (2025) eines interdisziplinären Teams von MIT, Princeton und Microsoft mit ca. 5000 Entwicklern ergab: Mit KI stieg die Zahl wöchentlich abgeschlossener Tasks im Durchschnitt um über 25 %, wobei Junioren am stärksten profitierten.
Leistungsfähigkeit der Modelle
Zunächst entscheidet die Leistungsfähigkeit des Modells sowie die Qualität der Prompts über mögliche Effizienzgewinne. Je stärker oder passender das Modell und je besser der Prompt, umso besser das Ergebnis.
Die Leistungsfähigkeit eines Modells wiederum hängt neben Architektur und Parameterumfang maßgeblich vom Trainingsmaterial ab. Dies erklärt, warum KI bei dem Generieren von Code in bestimmten Sprachen besonders gute Ergebnisse zeigt. Das gilt vor allem für JavaScript gefolgt von Python und TypeScript, wie der MultiPL-E-Benchmark zeigt. Statisch getypte Enterprise-Sprachen wie Java und C# liegen rund 10 Punkte dahinter – vor allem wegen strengerer Compiler-Fehler und geringerer Trainingsdatenmenge.
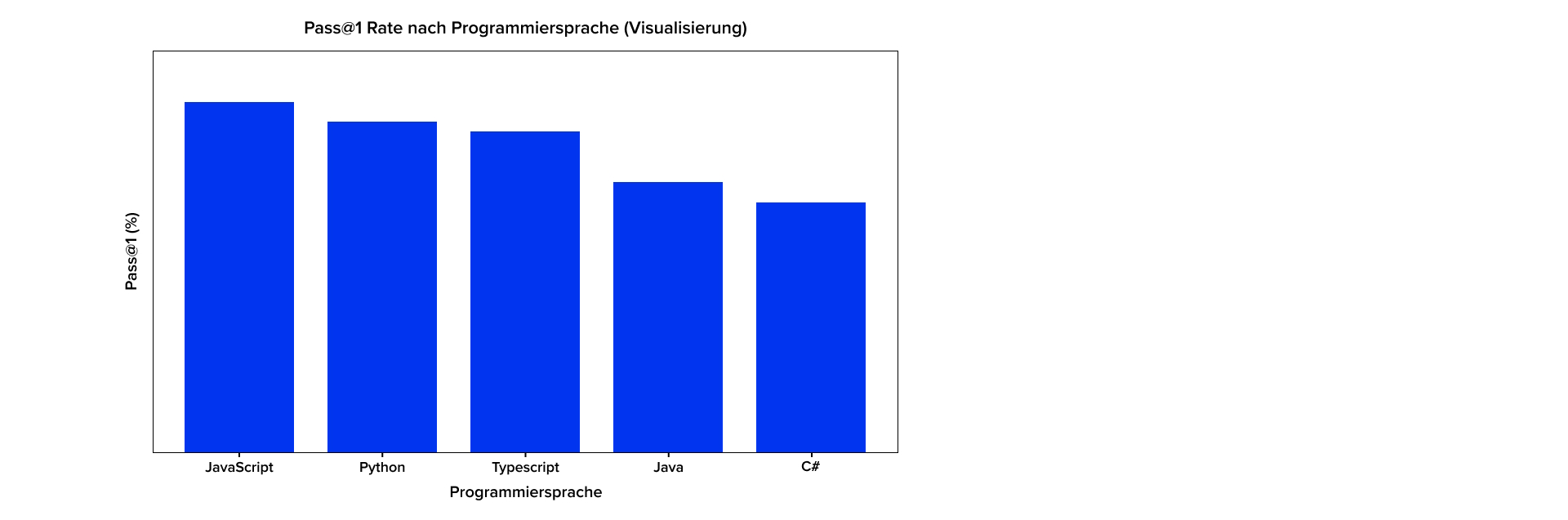
Der Firmen-Report Experience with GitHub Copilot for Developer Productivity at Zoominfo (2025) zeigt ähnliche Ergebnisse. In einem Versuch mit ca. 400 Devs wurden akzeptierte KI-Vorschläge pro Sprache gemessen. TypeScript, Java, Python und JavaScript lagen vorne, während andere Sprachen (HTML, JSON, SQL) klar zurückfielen.
Vereinfacht: Je weniger Trainingsmaterial, desto schlechter die Ergebnisse. Dies kann insbesondere im Legacy-Umfeld zum Tragen kommen, z. B. bei Codebasen, die spezielle oder nicht quelloffene Libraries und Frameworks nutzen. In diesen Umfeldern „performt“ KI schlechter.
KI hilft nicht überall gleichermaßen gut
Das Potenzial einer KI wird neben der Modellleistung vor allem durch die Komplexität der Aufgabe und ihren Kontext bestimmt. Besonders gut bewältigt KI derzeit einfache, in der Codebasis klar abgrenzbare Aufgaben, z. B. einzelne Codezeilen, neue Funktionen, Tests oder Refactorings innerhalb einer Codedatei.
Komplexe Aufgaben setzt KI derzeit deutlich schlechter um, wie auch die Studie Unleashing developer productivity with generative AI von McKinsey zusammenfasst. Im Vergleich zu einfachen abgegrenzten Aufgaben (bis zu +50 %) schrumpft der Zeitgewinn bei komplexen Aufgaben auf unter 10 %. Das sind z. B. viele Codedateien umspannende Aufgaben, Bugfixing oder architekturelle Änderungen in komplexen Codebasen mit mehreren heterogenen Technologien und Abhängigkeiten.
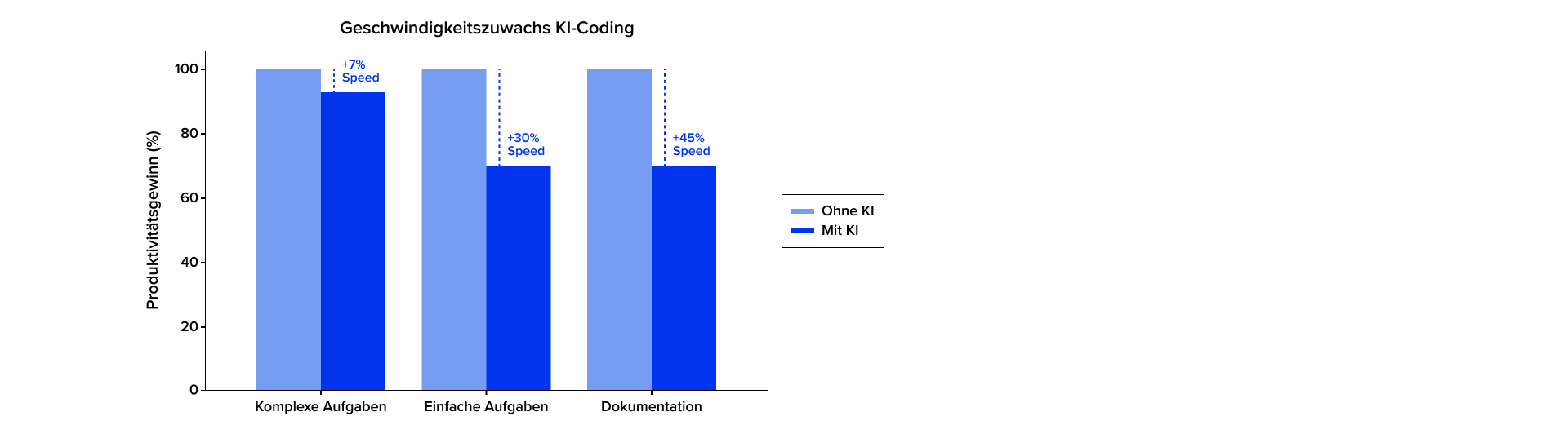
Ein weiterer Faktor ist der Grad an notwendigem Domänenwissen für eine Aufgabe. Die Unterstützung durch KI nimmt ab, je mehr Domänenwissen notwendig ist, um die Aufgabe richtig umzusetzen. Dieses Domänenwissen liegt in der Regel bei erfahrenen Entwickler:innen.
Das kann dazu führen, dass Junior-Entwickler:innen bei Routineaufgaben Tempo gewinnen, bei fachlich komplexen Fällen jedoch zurückfallen, weil ihnen Domänenwissen oder technisches Know-how zur Validierung der KI-Vorschläge fehlt.
Brutto vs. Netto
Ein weiterer Grund für die abweichenden Studienergebnisse ist der betrachtete Zeithorizont: Viele Analysen messen ausschließlich die Zeitersparnis beim Coden. Neuere Arbeiten erfassen dagegen den gesamten Software-Lifecycle – dort ist das Programmieren nur ein Teilaspekt, sodass der Netto-Gewinn pro Projekt deutlich kleiner ausfällt.
Eine pauschale Verteilung der Arbeitsaufwände lässt sich nicht angeben, da dies von Projekt zu Projekt stark variiert. B. Boehm nennt in seinem Buch Software Engineering Economics (1981) einen Coding-Anteil von 30 % für kleine Projekte und 20 % für große.
Wenn durch KI-basierte Assistenten der Codingprozess um z. B. 50 % beschleunigt werden kann, ergibt das bei einem Coding-Anteil von 20 % eine Effizienzsteigerung von 10 % für das Gesamtprojekt.
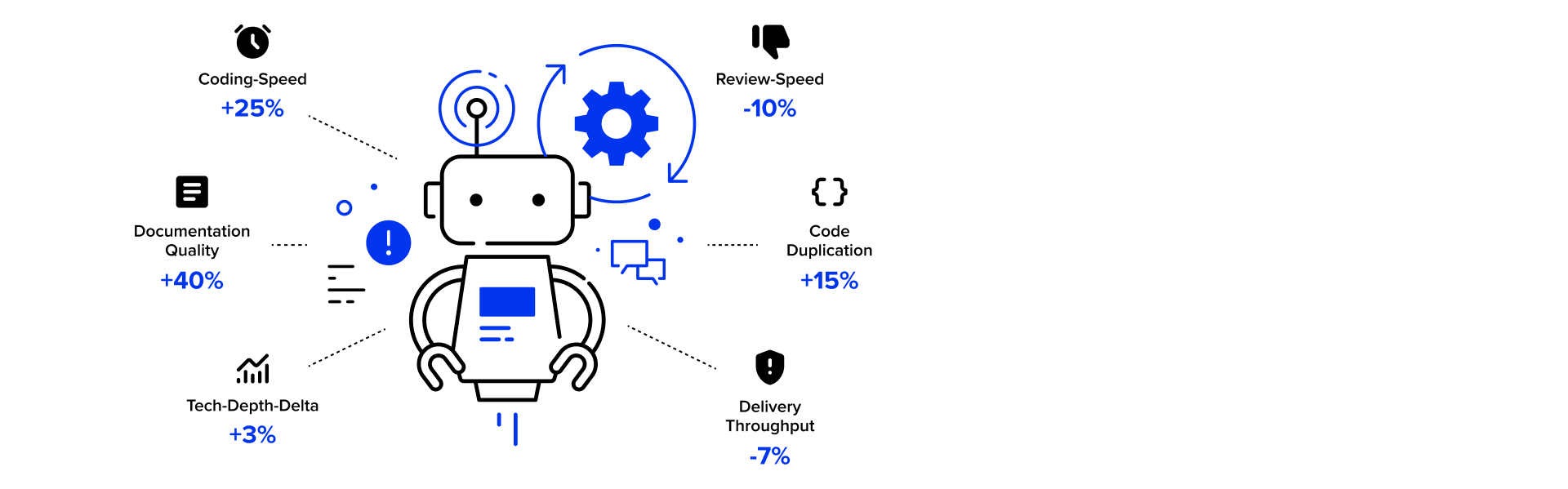
KI bringt nicht nur Vorteile
Der DORA Report Impact of Generative AI in Software Development (2025) analysierte Tausende Entwicklerbefragungen und Repository-Metriken. Ergebnis: Ein höherer KI-Adoptionsgrad korreliert mit mehr individueller Produktivität, schnelleren Code-Reviews und gesteigerter Qualität der Dokumentation – gleichzeitig sinkt jedoch der Delivery-Throughput. Effizienzgewinne kommen also nicht automatisch auf Systemebene an.
Ähnliches zeigt auch The State of Software Delivery (2025) von Harness: Über 65 % der 500 befragten Tech-Verantwortlichen berichten von fehlerhaften Deployments bei mindestens jeder zweiten Nutzung sowie zusätzlich notwendigem Debugging und Security-Fixing.
Neue Aufgaben
Gerade im Brownfield- und Enterprise-Umfeld entstehen durch den Einsatz von KI neue Aufgaben. Generierter Code muss verstärkt auf Sicherheit und Compliance-Aspekte hin überprüft werden. Auch werden Projekt-Standards nicht automatisch durch die KI beachtet.
Gleichzeitig verschärfen neue Vorgaben den Rahmen: Seit August 2024 gilt der EU AI Act, der schrittweise in Kraft tritt und für Hochrisiko-Systeme Transparenz, Risikobewertungen und Audit-Trails verlangt; parallel definiert die Norm ISO/IEC 42001 ein KI-Managementsystem mit klaren Rollen und Monitoring-Pflichten. In Deutschland ist bei externen LLMs z. B. ein Transfer-Impact-Assessment nach Art. 44 ff. DSGVO erforderlich, vor allem bei US-Hosting. Ergänzend helfen Software Bills of Materials (SBOM) und Attribution-Scans, Lizenzkonflikte zu vermeiden, weil generative Modelle urheberrechtlich geschützten Code replizieren können.
Zudem erhöht sich der Review-Aufwand. Da KI beliebig viel Code auf Knopfdruck erzeugt, müssen Entwickler:innen anschließend mehr Zeit darauf verwenden, diesen zu verstehen und zu validieren. Dadurch, dass sie den Code nicht selbst geschrieben haben, entfällt auch der Prozess, sich lange und intensiv mit der Umsetzung in der Codebasis auseinandergesetzt haben.
Schnell entwickelt, schlecht geliefert?
Die Stanford-HAI-Studie Do Users Write More Insecure Code with AI Assistants? (2023) zeigt, dass mit KI die Zahl korrekter Lösungen sinkt und die Menge im Code enthaltener Vulnerabilitäten steigt.
Eine Analyse der University of San Francisco und dem Vector Institute Security Degradation in Iterative AI Code Generation: A Systematic Analysis of the Paradox (2025) bestätigt das Bild: In 400 simulierten Refactoring-Iterationen stieg die Zahl kritischer Schwachstellen um etwa 38 %. Die Autor:innen schlussfolgern, dass ohne explizite Human-Review jede weitere KI-Änderung die Angriffsfläche vergrößert, weil Modelle zwar plausible, aber nicht verifizierte Änderungen erzeugen.
Entwickler:innen verlassen sich jedoch zunehmend auf Vorschläge der KI und verzichten vermehrt auf bewährte Prüf- und Review-Verfahren. Kriterien wie Lesbarkeit, Wartbarkeit und Dokumentation geraten in den Hintergrund; fehlerhafter Code wandert ungeprüft in die Codebasis. Das Ergebnis ist technische Schuld.
Technische Schuld durch den Einsatz von KI?
Aktuelle Umfragen unter Tech-Verantwortlichen zeigen, dass bewährte Softwareentwicklungsprinzipien wie DRY („Don’t Repeat Yourself“) bei der Nutzung von KI leiden. Diese Prinzipien dienen einem zentralen Zweck: die langfristige Wartbarkeit und Qualitätssicherung von Software. Werden sie ignoriert, wächst die technische Schuld.
Der AI Copilot Code Quality Report (2025) von GitClear unterstreicht das. Die Analyse von mehr als 200 Millionen Codeänderungen ergab, dass sich Commits mit Codezeilen-Duplikaten seit 2022 um den Faktor 4 häufen. Auch der DORA-Report warnt: der Einsatz von KI kann zu einer Verringerung der Lieferstabilität führen.
Dies zeigt, dass die Optimierung des Entwicklungsprozesses nicht automatisch die Softwareauslieferung verbessert.
Und nun? Doch keine KI-unterstützte Entwicklung?
Die Zeitersparnis durch KI-Coding ist stark kontextabhängig und wird häufig durch Mehraufwand an anderer Stelle relativiert – etwa durch längere Reviews, zusätzliche Korrekturen und rechtliche Prüfungen. Zudem können sinkende Lieferstabilität und wachsende technische Schuld die Folge sein; das vermeintliche Effizienztool bremst im Extremfall sogar.
Heißt das, wir sollten KI meiden? Ganz im Gegenteil. Das Potenzial ist riesig, zumal Tools und Modelle sich rasant weiterentwickeln. Projekte werden dadurch aber nicht automatisch und nicht sofort um 50 % schneller. Überhaupt sollte der Einsatz von KI nicht ausschließlich dem Produktivitätsgewinn dienen. Vielmehr lohnt der Blick auf weitere Benefits, wie etwa:
- Developer Experience: weniger Boilerplate, mehr Raum für kreative Aufgaben, schnellere Einarbeitung in neue Technologien.
- Qualität: sauberer Code und bessere Dokumentation.
- Rapid Prototyping: Ideen in Stunden statt Tagen verproben.
- Time-to-Productivity: kürzere Ramp-up-Phasen für neue Teammitglieder.
- Talentbindung: moderne Tools steigern Zufriedenheit und Attraktivität des Arbeitgebers.
KI erfolgreich einführen
Um positive Effekte über den gesamten Entwicklungszyklus hinweg zu heben, gilt es sicherzustellen, dass die Qualität nicht leidet und keine zusätzliche technische Schuld aufgebaut wird. Hier helfen klassische Entwicklungstugenden und Best Practices, die im Zuge der Einführung von KI noch mal auf den Prüfstand gestellt werden sollten. Es braucht einen klaren Governance-Rahmen, geschulte Teams und Kennzahlen, die Fortschritt sowie Risiken sichtbar machen.
Die folgenden Maßnahmen können dabei helfen, den Wertschöpfungsbeitrag von KI in der Software-Entwicklung langfristig zu steigern.
- KI-Strategie & Richtlinie: Ziele, Rollen, Prompt-Leitplanken und Review-Pflichten in einer verbindlichen KI-Richtlinie verankern (hierbei kann ein KI-Assessment unterstützen); Kosten- und Lizenzmodell evaluieren und ein Tech-Debt-Budget festlegen.
- KI-Weiterbildung: Entwickler:innen im Umgang mit neuen KI-Tools und effektivem Prompt-Engineering coachen und Stärken und Schwächen generativer KI vermitteln.
- (Re-) Etablierung klassischer Software-Entwicklungs-Prinzipien: Einführung von KI als Anlass nehmen, Dokumentationskultur sowie SOLID, DRY, TDD & Co zu erneuern; Teams regelmäßig in modernen Software-Engineering-Methoden schulen.
- Qualitätsmanagement & CI/CD: CI-Pipeline um SBOM, LLM-Attribution-Scanner und Lizenz-Checker erweitern; Pair programming mit KI ergänzen, nicht ersetzen.
- Senior-Gate & KPIs: Jede KI-Einfügung erst nach Vier-Augen-Prinzip bzw. Freigabe erfahrener Devs mergen; Kennzahlen wie „Tech-Debt-Delta nach AI-Merge“, Clone-Rate, Defect-Rate und Review-Coverage monatlich tracken.
Ob all das wirkt, zeigen Kennzahlen wie Refactoring-Quote, Lieferstabilität (Throughput) und Compliance-Violations, die in Projekten zusätzlich zu Kosten pro Seat erhoben und ausgewertet werden.
Fazit
Generative KI nimmt Entwickler:innen die Tipp-Routine ab, ersetzt aber keine bewährten Engineering-Praktiken. Teams, die Policies, Tests und Reviews vernachlässigen, handeln sich mehr Fehler, höhere Kosten und TechDebt ein. Mit klarer Governance, Training und messbaren KPIs dagegen wird KI zum nachhaltigen Beschleuniger: Code, Tests und Doku entstehen schneller, während Wartbarkeit und Compliance erhalten bleiben und die Developer Experience steigt.

Head of Technology